 Sage.is
Sage.is

Back in March 2016, a post appeared on the Google Testing Blog with a title that read like a memo and landed like an obituary.
"From QA to Engineering Productivity," the memo announced, and in the space of a few paragraphs it described how Google had dissolved the role of Software Engineer in Test (SET). Google replaced the Software Engineer in Test engineers with a new designation for all engineers: Software Engineer, Tools and Infrastructure (SETI).[1]
The change was not presented as a loss. It was presented as an evolution. Quality, the post explained, was no longer a function. It was a property of the engineering culture itself. Everyone owned it. Therefore no one needed the title.
Facebook had arrived at the same conclusion years earlier, though by a different route. Facebook never built a dedicated QA organization in the first place. An ex-Facebook engineer confirmed that the company employed no pure quality control roles.[2] Developers wrote their own tests. The company dogfooded[3] aggressively, releasing to employees first, then to small groups of real users, then worldwide. The philosophy was simple: ship fast, measure everything, fix what breaks, when it's worth it. Testing was embedded in the culture. A separate department for it would have been redundant.
The rest of the industry watched Google and Facebook and drew a lesson. If the two most successful software companies on earth did not need dedicated QA teams, neither did anyone else.
Gergely Orosz, a former engineering manager at Uber and the author of the Pragmatic Engineer newsletter (the largest paid technology newsletter in the world, with over a million subscribers), documented the pattern in a September 2023 analysis titled "How Big Tech Does Quality Assurance."[4] At his own team at Skype, Orosz wrote, the organization decided it made "zero sense" to have a dedicated test role when they shipped new features every day. The separate QA team was eliminated. Nine QA positions were converted to software development engineers. The testers were gone. The tests remained.
That distinction is the hinge on which this article turns. The tests remained. The thing the tests cannot do was lost.
What Testing Is, and What It Is Not

Johannes Vermeer, "The Lacemaker" (c. 1669-1671). Musée du Louvre, Paris. Meticulous, focused work where every stitch is deliberate and the quality is in the making, not the inspection. Public domain.
Testing verifies that code does what it was told to do. A unit test[5] checks that a function returns the expected output for a given input. An integration test[6] checks that two services communicate correctly. An end-to-end test[7] checks that a user can complete a workflow from login to checkout. All of these answer the same question: whether the software behaves as specified.
Quality assurance asks a different question. Not whether the code works, but whether the specification is correct. Whether the thing being built is the right thing. Whether it serves the user, accounts for edge cases the specification did not anticipate, interacts safely with the rest of the system, degrades gracefully, and avoids creating problems that will not surface for six months.
The distinction is structural. Testing is verification. QA is validation.[8]
Verification asks: did we build this thing right?
Validation asks: did we build the right thing?
The software industry spent fifteen years collapsing these two concepts into one. "Shift left" became the mantra: move testing earlier in the development cycle, embed it in the engineers, automate everything that can be automated.[9] The philosophy is sound. The execution was catastrophic, because what shifted left was testing. What fell off the table was Quality Assurance (QA).
Testing checks whether the code works. QA asks whether the code should exist. The industry automated the first and abandoned the second.
- Isabelle Plante
The Green Check Mark
A CodeRabbit analysis of 470 open-source pull requests, published in December 2025, found that AI-generated code contains approximately 1.7 times more issues per pull request[10] than human-written code.[11] AI-authored pull requests averaged 10.83 issues each, compared to 6.45 for human-written code. Critical issues appeared 1.4 times more often. Major issues appeared 1.7 times more often. Maintainability errors were 1.64 times higher. Logic and correctness errors were 1.75 times higher.
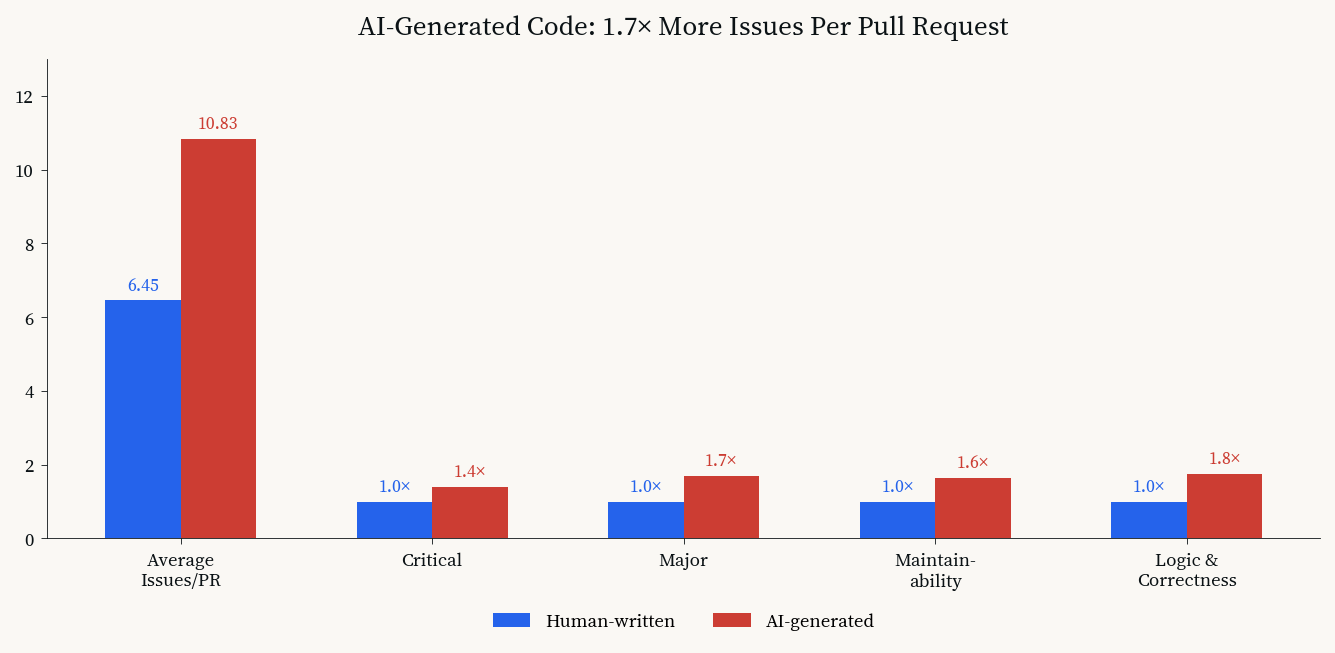
AI-generated code vs. human-written code: issues per pull request across five categories. Data: CodeRabbit, December 2025.
The Sonar State of Code Developer Survey for 2026 confirmed the pattern from the developer's own perspective: 61 percent of developers agreed that AI often produces code that "looks correct but isn't reliable."[12] The same percentage agreed that it takes significant effort to get good code from AI through prompting and fixing.
A large-scale empirical study published on arXiv in March 2026, analyzing AI-generated code in production repositories, found that 24.2 percent of tracked AI-introduced issues potentially survive in production, corresponding to 37.25 surviving issues per 100 AI-authored commits.[13] Security issues were the most likely to persist: 41.1 percent survived. Runtime bugs followed at 30.3 percent.
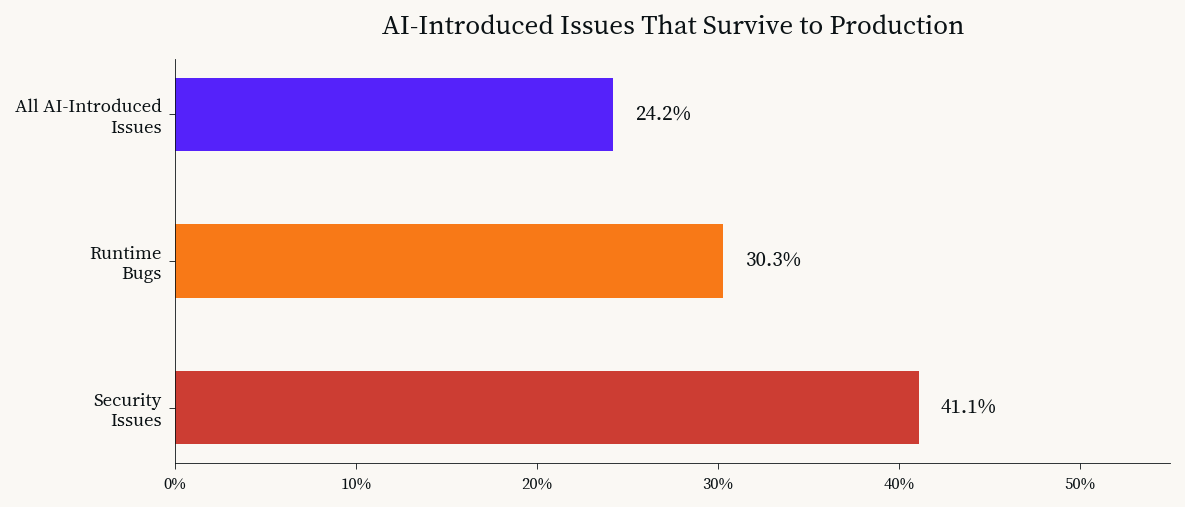
AI-introduced issues that survive to production. Security bugs are the most persistent. Data: arXiv, March 2026.
The numbers describe a specific failure mode: AI-generated code that passes its tests but contains problems the tests were not designed to catch.
✅ The tests pass because the AI wrote the tests.
✅ The AI wrote the tests to match the code.
✅ The code and the tests agree with each other.
✅ The green check mark appears.
✅ The pipeline is clean.
✅ The pull request ships.
Nobody asks whether the code should have been written that way. Nobody asks whether the tests measure the right things. Nobody asks because the role that used to ask was eliminated in 2016, and the industry has spent ten years pretending it was not needed.
The Compound Interest of Unmeasured Quality
The most dangerous property of poor quality assurance is that it compounds invisibly. A unit test catches a bug in hours. A missing QA practice produces a bug that appears in six months, after three other teams have built on the assumption that the original code was correct.
The Register reported in December 2025 that AI-authored code "needs more attention" and "contains worse bugs" than human-written code, noting that the bugs are not trivial: they are architectural, structural, and often invisible to the test suite because the test suite was designed around the same assumptions as the code.[14]
This is not a testing problem. It is a quality assurance problem. Testing catches the bugs that exist within the specification. QA catches the bugs that exist because the specification is wrong, or incomplete, or silently contradicts another specification three services away.
When Google eliminated its QA team, it replaced the function with a culture. James Whittaker, a former engineering director at Google and co-author of How Google Tests Software (2012), described the philosophy: at Google, product teams own quality, not testers.[15] Every developer is expected to do their own testing. The tester's job is to build the infrastructure and processes that support developer self-reliance.
Google spent years building that infrastructure. Spinnaker[16], Atlas, internal testing frameworks, bootcamps, cultural change programs. Then it removed the safety net. The industry copied the removal. It did not copy the years of infrastructure that preceded it.
When Everyone Owns Quality, Nobody Does

Rembrandt van Rijn, "The Syndics of the Drapers' Guild" (1662). Rijksmuseum, Amsterdam. Five inspectors of cloth quality, seated at a table, looking directly at the viewer. They had the title, the mandate, and the authority. Their chairs are no longer occupied. Public domain.
The phrase "everyone owns quality" contains a structural fallacy. In practice, distributed ownership of a non-functional requirement[17] means that quality competes for attention with every other priority on every developer's plate. Features have deadlines. Quality does not. Features have advocates (product managers, designers, customers). Quality does not, because the person whose job it was to advocate for quality was converted into a software development engineer in 2016.
The pattern is visible in incident data. A 2025 analysis from a major code review platform found that pull requests per author increased 20 percent year-over-year thanks to AI assistance, but incidents per pull request increased 23.5 percent.[18] More code shipped. More of it broke. The velocity graph went up. The reliability graph went in the other direction.
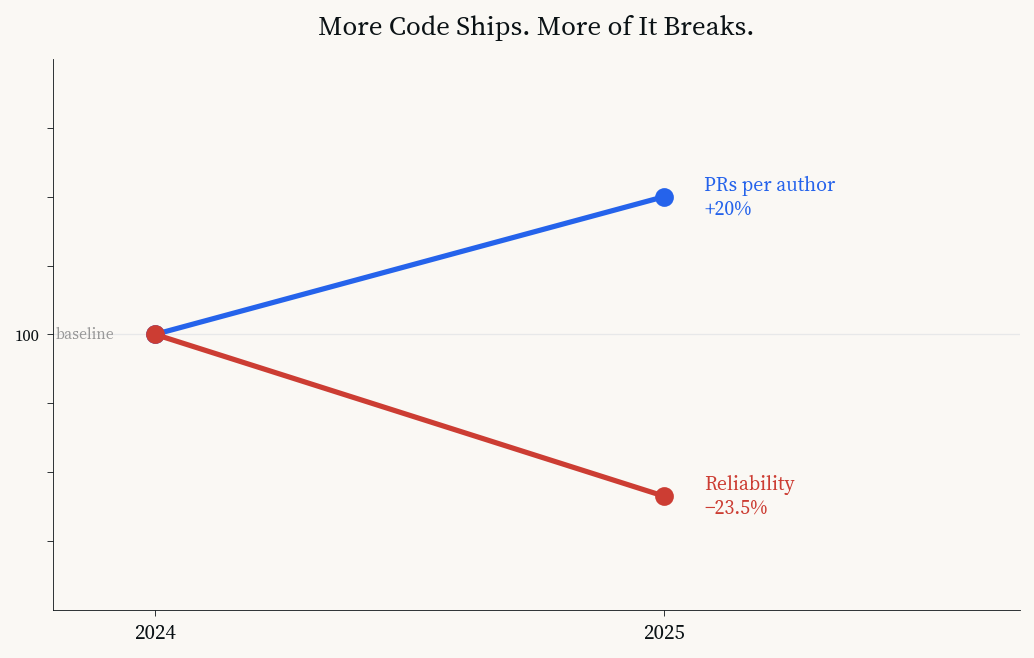
Velocity and reliability diverging: more code ships, more of it breaks. Data: CodeRabbit, January 2026.
That is the predictable outcome of removing the role whose job was to look at the system as a whole, not at the individual test. Testing is local. QA is systemic. A developer writing a test for their own code is performing a local verification. Nobody is performing the systemic validation, because nobody has the title, the mandate, or the time.
The AI Testing Paradox

Ford Madox Brown, "Work" (1852-1865). Manchester Art Gallery. Everyone is busy. The navvies dig, the flower seller sells, the pamphleteer distributes tracts. Activity everywhere, and nobody asking whether the road is being built in the right direction. Public domain.
AI coding agents have made the problem exponentially worse by making testing exponentially easier.
Claude Code, Cursor, Aider, Cline, and their competitors can generate comprehensive test suites in minutes. They write unit tests, integration tests, property-based tests, snapshot tests. The coverage numbers look excellent. The CI pipeline[19] glows green. The developer, reviewing the PR on a Monday morning after the agent ran overnight, sees passing tests across every module. Everything looks correct.
The paradox: the better AI gets at writing tests, the less meaning the tests hold. When the same system writes the code and the tests, the tests verify that the code is self-consistent. They do not verify that the code is correct in any external sense. They verify that the code does what the code does. That is a tautology[20], not a quality gate.
The Three Missing Gates
Quality assurance is not a test suite. It is three things that tests cannot be. To implement this with AI agents (or humans), we must do the following:
The first is the approval gate. Before any change ships, someone or something must determine whether the change should exist, whether it solves the right problem, and whether it introduces risks the specification did not contemplate. Cline, the open-source VS Code agent extension, implements this at the tool level: every terminal command and file edit requires explicit human approval before execution.[21] The agent cannot accidentally do something destructive, because the system asks first. This is a poka-yoke[22], a mistake-proofing mechanism borrowed from manufacturing, where Shigeo Shingo designed it for the Toyota Production System in 1961.
Shingo's insight: defects are not caused by workers. They are caused by processes that allow workers to make mistakes. The same is true of AI agents. The defects are not in the model. They are in the harness that fails to constrain it.
- Isabelle Plante
The second is the crash recovery layer. Every agent run should persist state to a durable store at each step. If the agent fails, the next run picks up where it left off. Gas Town, Steve Yegge's multi-agent workspace manager, implements this through git-backed persistence: all state is written to git hooks, and a crashed agent's work is recoverable from the last commit.[23] Without this, a failed twenty-minute agent run loses all work. With it, the system acknowledges that failure is normal and designs for recovery rather than perfection.
The third is the verification layer. After any agent produces output, a separate process (another agent, a deterministic script, a human reviewer) needs to verify the output against criteria the first agent did not write. This means we need to check the code not only to see if it works, but that it actually does what's needed. This needs to be done by an unbiased individual (AI or human) that did not have a hand in designing the code that's being verified and validated.
All three gates (approval, recovery, verification) are not tests. They are not part of a CI standard pipeline. They are the structural equivalent of the QA role that the industry eliminated, implemented as architecture rather than a job title.
QA is not a step in the pipeline. It is a way of thinking. You cannot automate it, because automation is what it evaluates.
- Alexander Somma
The Return of the Inspector
The tools already exist. Open-source agent harnesses[24] like Archon let teams define YAML[25] workflows that constrain agent behavior, preventing scope creep and unpredictable output.[26] Claude's Agent SDK isolates credentials in an OAuth vault, preventing the agent from leaking secrets.[27] Aider auto-commits every change with descriptive messages, making every agent action reversible with a single git revert.[28]
None of them are QA tools. They are engineering tools that implement QA principles. The distinction matters. QA was never about the tools. It was about the mandate: someone in the organization whose job required them to evaluate whether the right thing was being built, before the code was written, not after. Someone who looked at the system, not the function. Someone who represented the user, not the specification.
AI agents are the most powerful software engineering tools ever built. They are also the most powerful argument for quality assurance ever made. The more code an agent writes, the more tests an agent generates, the more pull requests an agent ships, the more critical it becomes to have a process (human, architectural, or both) that answers the question no test can answer: whether the right thing is being built.
The green check mark says the tests pass. It does not say the software is good. The gap between those two statements is where quality assurance used to live.
The chair is still empty. The question is whether you will fill it with a person, a process, or a principle, or whether you will keep staring at the green check mark and pretending it means what it used to mean.
Footnotes
Sage.is AI-UI is built by Startr LLC. The authors are co-founders. The article-quality-audit.py script referenced in this article is part of the Sage editorial pipeline. Full disclosure: we build tools that implement the patterns described in this article, and we believe the argument stands independent of the tools.
Google Testing Blog, "From QA to Engineering Productivity," March 2016. testing.googleblog.com. The post describes the transition from SET (Software Engineer in Test) to SETI (Software Engineer, Tools and Infrastructure). ↩︎
StickyMinds, "Facebook's No-Testing-Department Approach: An Interview with Simon Stewart." Simon Stewart, an engineering manager at Facebook, confirmed the company employs no pure quality control roles. stickyminds.com. ↩︎
Dogfooding (or "eating your own dog food") is the practice of using your own product internally before releasing it to customers. Companies release new features to employees first to catch bugs and usability problems before real users encounter them. The term has been in use in the technology industry since at least the 1980s. ↩︎
Gergely Orosz, "How Big Tech Does Quality Assurance (QA)," The Pragmatic Engineer, September 19, 2023. newsletter.pragmaticengineer.com. Orosz is a former engineering manager at Uber and author of the Pragmatic Engineer newsletter. ↩︎
A unit test is an automated check that verifies a single small piece of code (a function or method) produces the expected output for a given input. It is the smallest and most focused type of software test, typically written by the developer who wrote the code. ↩︎
An integration test is an automated check that verifies two or more software components or services work correctly when connected together. Where unit tests check individual parts in isolation, integration tests check the seams between parts. ↩︎
An end-to-end test is an automated check that simulates a real user completing an entire workflow from start to finish (for example, logging in, browsing products, adding items to a cart, and checking out). It tests the full system as a user would experience it. ↩︎
The verification/validation distinction is codified in IEEE 1012-2012 (Standard for System, Software, and Hardware Verification and Validation) and widely attributed to Barry Boehm's formulation: "Verification: Are we building the product right? Validation: Are we building the right product?" ↩︎
Shift left testing is the practice of moving testing activities earlier in the software development lifecycle, embedding quality checks into development rather than performing them at the end. The term originated in the testing community in the early 2010s and was widely adopted by 2015. The philosophy is sound; the problem was that what shifted left was automated testing, while systemic quality assurance fell out of scope. ↩︎
A pull request (often abbreviated PR) is a proposal to merge new code into a project's codebase. The developer submits their changes, other team members review the code, automated tests run against it, and if everything passes the code is accepted ("merged"). The green check mark appears on a pull request when all automated checks pass. ↩︎
CodeRabbit, "State of AI vs Human Code Generation Report," December 2025. coderabbit.ai. Analysis of 470 open-source pull requests. AI-authored PRs contained 1.7x more issues on average (10.83 vs 6.45). ↩︎
SonarSource, "State of Code Developer Survey Report 2026." sonarsource.com. 61% of developers agreed AI often produces code that "looks correct but isn't reliable." ↩︎
"Debt Behind the AI Boom: A Large-Scale Empirical Study of AI-Generated Code in the Wild," arXiv, March 2026. arxiv.org. Found 24.2% of AI-introduced issues survive in production; 41.1% of security issues persist. ↩︎
The Register, "AI-authored code needs more attention, contains worse bugs," December 17, 2025. theregister.com. ↩︎
James Whittaker, Jason Arbon, and Jeff Carollo, How Google Tests Software (Boston: Addison-Wesley, 2012). Whittaker was an engineering director at Google responsible for testing Chrome, Maps, and Google web apps. ↩︎
Spinnaker is an open-source continuous delivery platform originally built by Netflix and later adopted by Google. It automates the process of releasing software to production environments, handling deployment strategies, rollbacks, and multi-cloud orchestration. ↩︎
A non-functional requirement describes how a system should work rather than what it should do. Performance, security, reliability, accessibility, and quality are all non-functional requirements. They do not add features to a product; they determine whether the features are good enough to use. Non-functional requirements are notoriously difficult to test because they describe properties of the whole system, not individual functions. ↩︎
CodeRabbit, "2025 Was the Year of AI Speed. 2026 Will Be the Year of AI Quality," January 2026. coderabbit.ai. Pull requests per author increased 20% YoY; incidents per pull request increased 23.5%. ↩︎
A CI pipeline (Continuous Integration pipeline) is an automated system that runs tests, code quality checks, and builds every time a developer submits code. If all checks pass, the pipeline displays a green check mark. If any check fails, the pipeline blocks the code from shipping. The pipeline runs without human intervention. ↩︎
A tautology is a statement that is true by definition but conveys no new information. In logic, "A equals A" is a tautology. In this context, AI-generated tests that verify AI-generated code produce a tautology: the tests confirm that the code does what the code does, which tells you nothing about whether the code is correct in any external sense. ↩︎
Cline is an open-source VS Code extension that implements agentic coding with a visual approval system. Every terminal command and file edit requires explicit human approval before execution. Version 3.4 (February 2025) introduced the MCP Marketplace. ↩︎
Poka-yoke (ポカヨケ, "mistake-proofing") was formalized by Shigeo Shingo in 1961 as part of the Toyota Production System. Shingo distinguished between mistakes (inevitable human errors) and defects (mistakes that reach the customer). The goal of poka-yoke is to design processes so that mistakes are detected and corrected immediately, eliminating defects at the source. Originally called baka-yoke ("fool-proofing"), the name was changed in 1963 after a worker at Arakawa Body Co. objected to the term. ↩︎
Gas Town is a multi-agent workspace manager by Steve Yegge (released January 2026). It uses git-backed persistence: all agent state is written to git hooks, enabling crash recovery and durable multi-agent workflows. github.com/steveyegge/gastown. ↩︎
An agent harness is the software wrapper that controls an AI agent's behaviour: what tools it can access, what approvals it needs, how it handles errors, and how it reports what it did. The harness drives the loop (plan → execute → inspect → repeat); the AI model provides the reasoning. Different harnesses give the user different levels of control over the agent's actions. ↩︎
YAML (YAML Ain't Markup Language) is a human-readable data format used for configuration files. It uses indentation and simple punctuation rather than the brackets and braces of formats like JSON. In the context of AI agent frameworks, YAML files define the rules and workflows that control how agents operate, what steps they follow, and what constraints they must respect. ↩︎
Archon is an open-source project that lets developers define agent workflows in YAML, constraining agent behavior by specifying steps, dependencies, and handoff points. The harness is the guardrail. mindstudio.ai. ↩︎
Claude Agent SDK (formerly Claude Code SDK) decouples credentials from the agent harness using an OAuth vault. The agent calls MCP tools via a proxy; the proxy fetches credentials from the vault per-session. The harness never sees the tokens. anthropic.com. ↩︎
Aider is an open-source CLI pair-programming tool with 43,000 GitHub stars. It auto-commits every change with descriptive git messages, making every agent action reviewable and reversible. aider.chat. ↩︎